RAG 和 Agent 别再混着用了:一篇讲清分工、组合与落地顺序

封面图:如果把这篇先压成一眼能懂的画面,大概就是这样。左边负责把资料和证据找回来,右边负责拿着上下文把事做下去,中间最关键的是交接。
这两年很多 AI 产品介绍里,RAG 和 Agent 经常被放在一起讲,听久了很容易产生一种错觉:只要模型会检索、会调用工具、会多轮推理,这些东西差不多就是一回事。
但真到了落地阶段,这种混用会很快带来问题。有人把本来适合做检索问答的系统做成了复杂 Agent,结果成本高、延迟大、稳定性差;也有人把本来需要行动能力的任务硬塞进 RAG,最后模型只能“知道”,却做不了事。
最近整理了一批本地资料,里面既有检索、向量库、混合搜索,也有工具调用、上下文注入、自动化和多代理协作。抽出来以后,我越来越觉得:RAG 和 Agent 最重要的不是谁更高级,而是它们解决的问题完全不同。
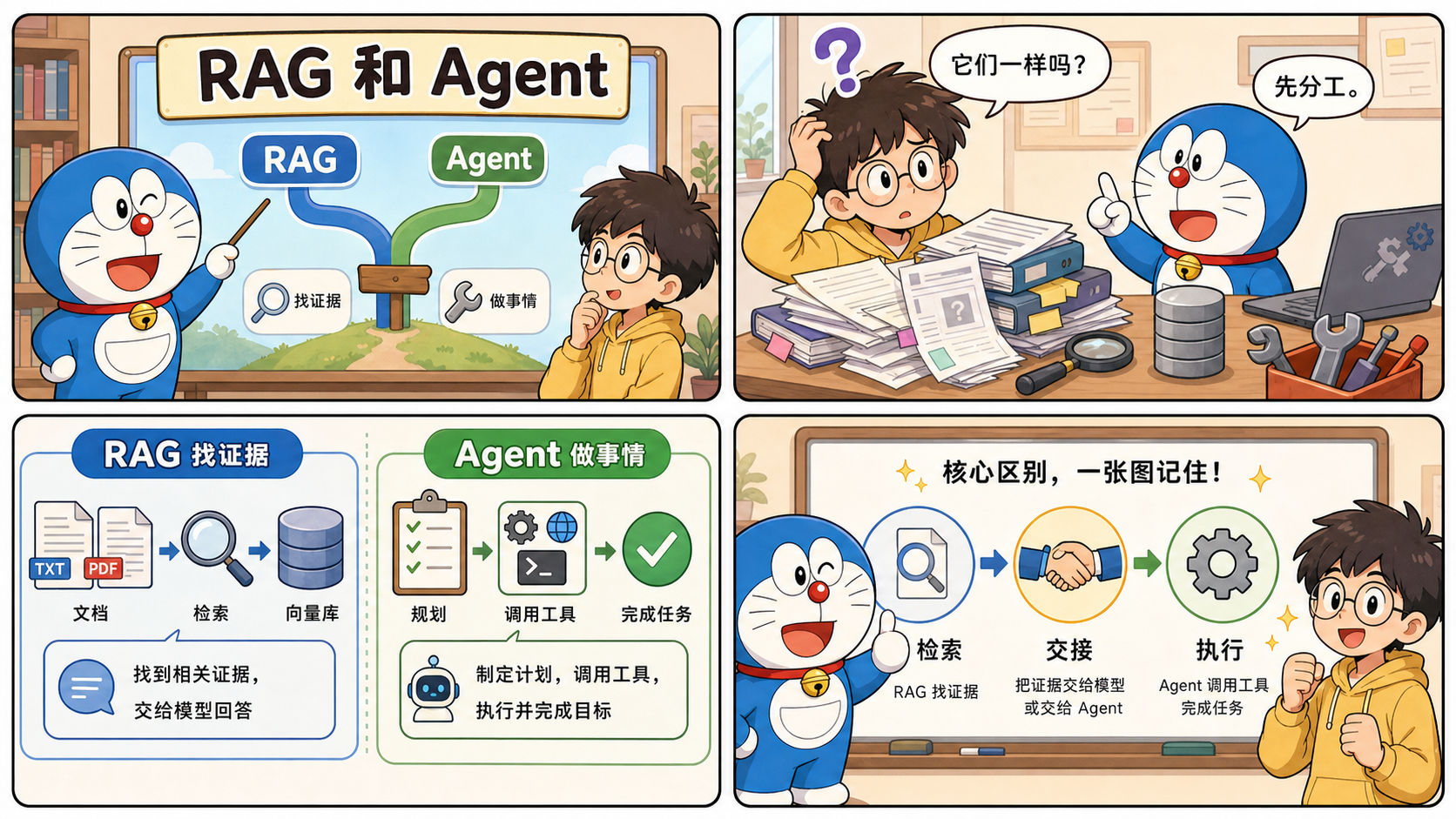
图 1:把它们想成两种不同角色会更好理解。RAG 更像先把资料和证据找对的人,Agent 更像拿着上下文和工具把事情做下去的人。
RAG 解决的是“模型不知道”的问题
RAG,检索增强生成,本质上是在回答前先补证据。
它最适合的场景通常有几个共同点:
- 问题依赖外部知识,而这些知识不稳定、更新快,或者根本不在模型参数里
- 你希望回答尽量基于真实文档,而不是模型自由发挥
- 你更关心“答得准不准”,而不是“会不会自己行动”
比如:
- 企业内部知识库问答
- 产品文档搜索
- 法务、金融、医疗类的资料辅助查询
- 会议纪要、笔记、日报的语义搜索
这类问题的核心不是“推理链多长”,而是能不能先把对的材料找回来。
所以一个像样的 RAG 系统,重点通常都落在这些地方:
- 文档怎么切分,既不丢语义,又不让块太大
- 元数据怎么设计,能不能按时间、部门、来源做过滤
- 检索是不是只靠向量,还是需要关键词 + 向量的混合检索
- 首轮召回之后,要不要再做 rerank
- 最后拼进上下文的内容是不是有重复、冲突或者噪音
说白了,RAG 的第一目标不是“聪明”,而是把上下文准备对。
Agent 解决的是“模型知道了以后要怎么做”的问题
Agent 则完全是另一类能力。
它关心的不是有没有资料,而是模型能不能围绕一个目标,调用工具、拆分步骤、处理中间状态,并最终把事情做完。
典型任务包括:
- 读一个 GitHub issue,然后修改代码、跑测试、提交结果
- 收到告警后先查日志、再定位服务、最后生成排障摘要
- 定时执行例行任务,比如日报、巡检、内容聚合、监控
- 在多平台之间转发、整理、归档信息
这类任务即使完全不需要 RAG,依然需要 Agent,因为难点不在知识召回,而在:
- 如何规划下一步动作
- 什么时候该调用哪个工具
- 工具失败后怎么重试或降级
- 中间产物是否需要保存
- 任务什么时候可以安全结束
如果说 RAG 像“先去图书馆找参考资料”,那 Agent 更像“拿着目标开始干活的人”。
真正常见的形态,不是二选一,而是先检索,再行动
很多真实系统里,RAG 和 Agent 不是替代关系,而是前后衔接。
一个很实用的理解方式是:
RAG负责把当前任务最相关的上下文找出来Agent负责基于这些上下文去判断、调用工具和执行动作
中间最关键的一步,是上下文注入。
也就是说,检索系统不一定直接产出最终答案,它也可以只做一件事:在模型真正开始这一轮推理前,把召回到的内容注入到当前输入里。这样做有几个好处:
- 检索结果只服务当前任务,不会污染长期会话历史
- 系统提示词可以保持稳定,更利于 prompt cache
- 记忆、RAG、规则约束这些能力都能作为“当前轮的补充上下文”接进去
这个边界非常重要。很多系统失败,不是因为没做检索,而是把检索、记忆、历史对话和系统规则全部混进一个大 prompt,最后谁也管不好。

图 2:更常见的真实流程不是二选一,而是先检索、再交接。RAG 先把当前任务需要的证据备好,Agent 再基于这些证据决定下一步。
记忆不是 RAG,RAG 也不是会话历史
这三个概念尤其容易被混掉。
1. 会话历史
它记录“这次对话里刚刚发生了什么”。
适合保存:
- 用户刚刚提的问题
- 模型上一轮给出的回答
- 当前任务里的中间步骤
2. 记忆
它记录“这个用户长期稳定的偏好和背景”。
适合保存:
- 用户喜欢什么表达风格
- 用户常做什么类型的任务
- 过去哪些决策对后续仍有帮助
3. RAG
它记录“当前问题需要查阅的外部证据”。
适合连接:
- 文档库
- 笔记库
- 项目资料
- 工单、会议纪要、知识图谱
一个常见误区是把记忆当成事实库,把 RAG 当成万能补丁。实际上更稳的做法通常是:
- 用记忆保存偏好和长期画像
- 用会话历史保存当前轮次上下文
- 用 RAG 在需要时拉取外部材料
三者分工越清楚,系统越容易维护。

图 3:这三个容器最怕混着装。会话历史记录刚刚发生了什么,记忆保留长期稳定的信息,RAG 则临时拉取这一题真正需要查阅的外部材料。
怎么判断一个需求该先上 RAG,还是先上 Agent?
我现在更偏向用下面这套判断:
优先上 RAG 的情况
- 用户主要是在“问”
- 结果主要是“回答”或“总结”
- 数据源比较明确,能构成稳定语料库
- 你最担心的是幻觉和证据缺失
比如“帮我从公司的产品文档里回答配置问题”,这就是典型 RAG 问题。
优先上 Agent 的情况
- 用户主要是在“让系统做事”
- 任务涉及调用外部工具
- 需要多步决策或状态跟踪
- 需要自动化、调度或跨平台执行
比如“每天早上汇总行业新闻并发到群里”,这显然已经不是单纯问答。
同时需要两者的情况
- 既要先查资料,又要根据资料采取行动
- 任务长,且上下文来自多个来源
- 你需要结果可执行,而不是只可阅读
比如“收到告警后先查 runbook,再看日志,再输出处理建议”,就是很典型的“RAG + Agent”。
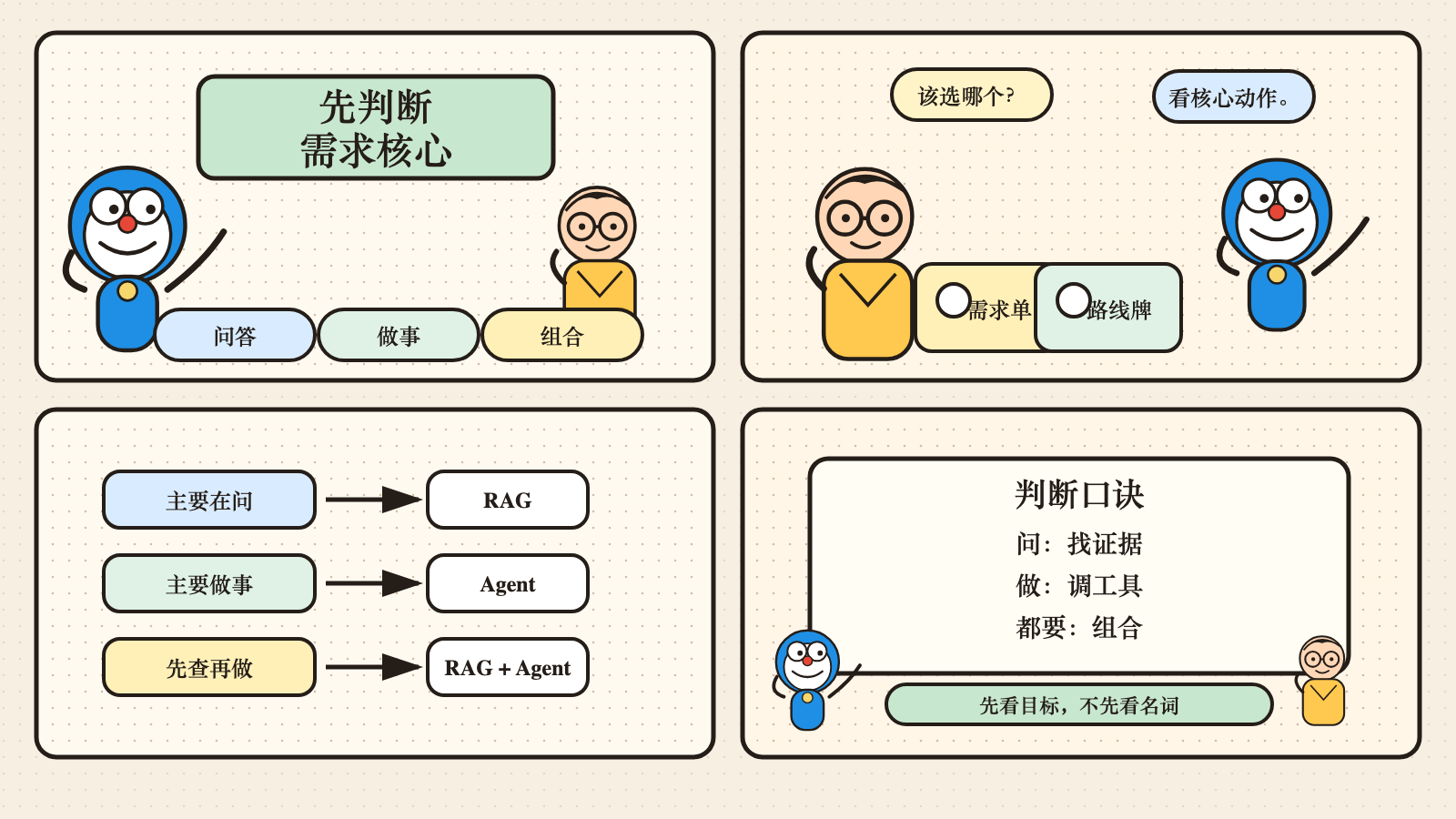
图 4:判断该先上 RAG 还是先上 Agent,最实用的起点不是看名词,而是先看这个需求的核心,到底是在回答问题,还是在把事情做完。
那目前常见的 RAG 数据库怎么选?
这里我想先说一个经常被忽略的事实:很多 RAG 效果问题,并不是数据库选错了,而是切块、元数据、过滤、重排和上下文拼装没有做好。
数据库更像是你的底座,它主要影响的是:
- 你是更适合快速原型,还是直接面向生产
- 你能不能方便地做 metadata filter、hybrid search 和 rerank
- 数据量变大以后,系统是平滑扩展,还是很快撞墙
- 你愿不愿意自己运维,还是更想用全托管
所以“哪个库最好”这个问题通常问得不太对。更实用的问法往往是:我现在最缺的是本地开发体验、生产能力、还是运维省心?
再补一个很重要的边界:FAISS 很强,但它更像一个高性能向量检索库,不是一套完整的生产数据库;而 Qdrant、Weaviate、Milvus、Pinecone、Chroma 这些,才更接近大家平时说的 RAG 数据库。
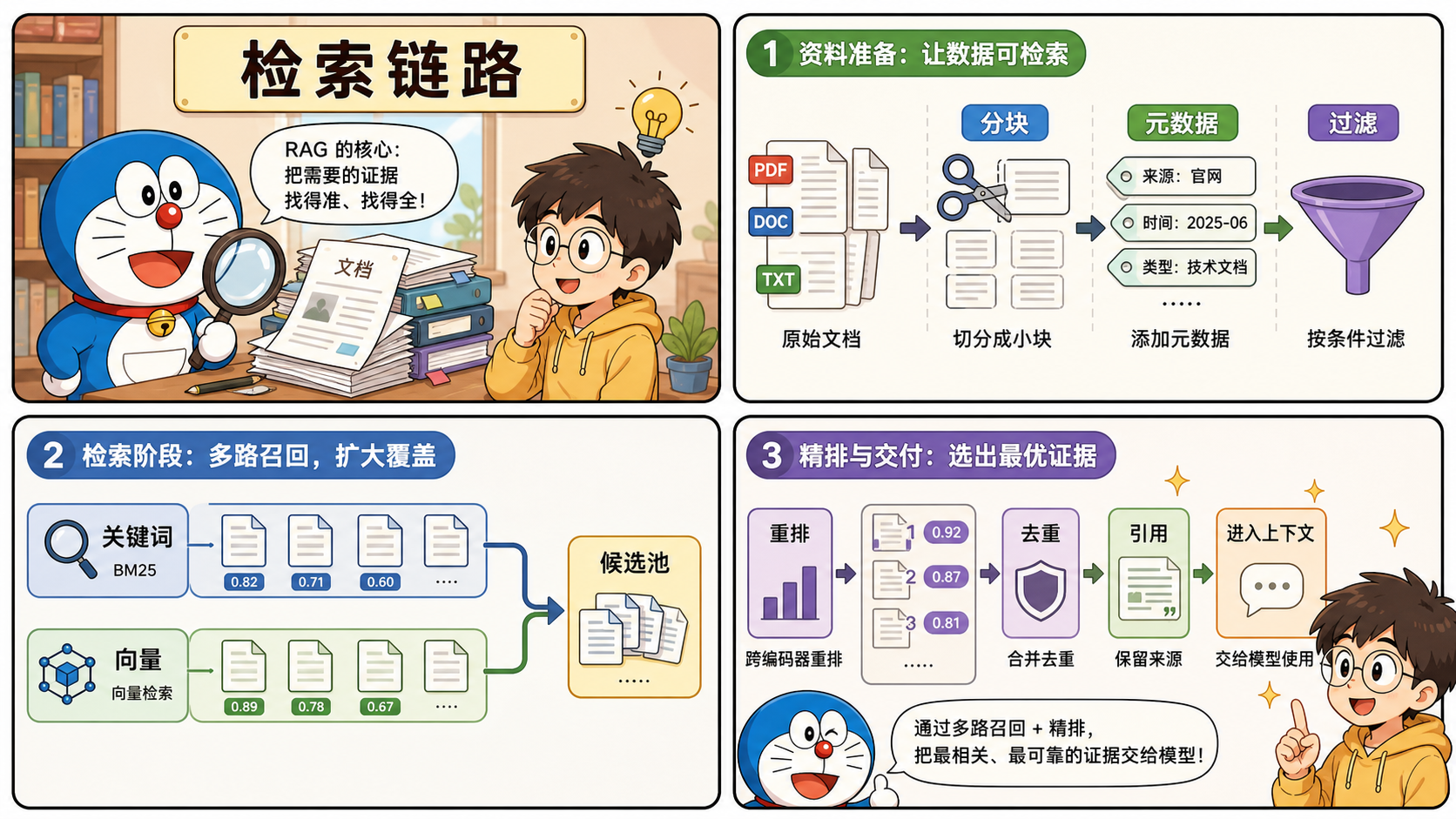
图 5:数据库不是唯一重点。真正决定 RAG 质量的,往往是语料清理、结构分块、metadata、hybrid 检索、rerank 和后续评估这一整条链路。
先给一个够用的结论
如果你只是想先有一个不折腾的判断,我现在会这么分:
- 个人项目 / 原型阶段:优先看
Chroma、Qdrant - 既想自托管,又认真考虑生产:优先看
Qdrant、Weaviate - 明确是大规模分布式场景:优先看
Milvus / Zilliz Cloud - 完全不想碰基础设施:优先看
Pinecone - 离线实验、召回基线、算法研究:优先看
FAISS
一张实用对比表
| 方案 | 更像什么 | 更适合什么场景 | 我会优先看它的原因 | 需要提前知道的点 |
|---|---|---|---|---|
FAISS | 向量检索库,不是完整数据库 | 本地实验、离线批处理、召回基线、追求极致性能 | 索引类型非常多,Flat / IVF / HNSW / PQ 这些都很成熟,适合把“检索本身”先跑明白 | 你得自己补持久化、过滤、权限、多租户、云化和服务层 |
Chroma | 本地友好的嵌入数据库 | 个人知识库、Agent 本地检索、小中型原型 | 上手快,支持文档与 metadata,官方文档现在也明确支持 dense、sparse、hybrid search,以及 self-host 和 cloud | 更偏轻量和快速迭代,我通常把它看成“开发体验很好”的选择,而不是先入手就奔着超大规模 |
Qdrant | 很均衡的生产型向量数据库 | 既要原型速度,也要往生产平滑长大 | metadata filter、dense+sparse、hybrid search、多向量、late interaction 这些都比较顺,托管云、自托管、Hybrid Cloud 也都有 | 比 Chroma 更重一些,认真上生产时还是要规划分片、资源和检索链路 |
Weaviate | 一体化更强的 AI 数据库 | 想要比较完整的“数据库 + 检索 + 模型集成”体验 | 内建 vector + BM25 hybrid、过滤、multi-tenancy、压缩、managed 和 self-hosted 都比较完整 | 体系更大,概念更多,适合愿意接受它整体工作方式的团队 |
Milvus / Zilliz Cloud | 偏分布式的数据平台 | 数据量大、吞吐高、复杂检索、云上生产 | 对大规模检索和分布式扩展很有吸引力,官方文档里也把 metadata filter、multi-vector hybrid search 讲得很明确 | 对个人项目来说通常偏重,工程和运维复杂度也更高 |
Pinecone | 全托管 serverless 向量数据库 | 不想运维、想直接上线、团队更看重工程效率 | 托管体验很强,dense / sparse / hybrid、metadata filtering、integrated embedding、serverless 成本模型都比较清晰 | 更依赖供应商的成本模型和限制,官方文档也明确提到它是 eventually consistent,不是那种完全自己掌控底层的路线 |
逐个说人话一点
1. FAISS:适合把“检索本身”先研究透
很多人一说 RAG 数据库就把 FAISS 放进去,但我其实更愿意把它单独看。
原因很简单:它非常强,尤其适合做向量检索实验和基线验证,但它不是一套开箱即用的生产数据库。
它特别适合这些情况:
- 你想快速验证 embedding 模型效果
- 你想比较不同索引结构的召回和延迟
- 你在做离线评估、批处理或研究型工作
如果你现在连“这批数据大概该用 Flat、IVF 还是 HNSW / PQ”都还没概念,FAISS 反而是很好的起点。
但如果你下一步就要做:
- metadata 过滤
- 多租户
- 服务化 API
- 高可用
- 云上扩缩容
那你迟早还是会走向真正的数据库产品。
2. Chroma:很适合个人项目和快速原型
Chroma 给我的感觉一直是:它很懂开发者在早期到底想要什么。
你通常不会在一开始就需要一整套复杂基础设施,你更需要的是:
- 很快把数据塞进去
- 很快查出来
- 顺手带上 metadata
- 本地就能反复试
如果你做的是:
- 个人知识库
- 笔记检索
- 本地 Agent 的资料召回
- 一个还在验证 PMF 的小应用
Chroma 往往是很顺手的。
我会把它放在“先跑起来、先验证有效性”的一侧。
如果后面你发现:
- 过滤条件越来越复杂
- 数据量明显变大
- 你开始认真做 hybrid / rerank / 云化部署
那时再评估要不要迁到更偏生产型的底座,也完全正常。
3. Qdrant:我现在会优先给很多团队看的均衡选项
如果你问我“现在有没有一个不那么偏科的选择”,Qdrant 大概率会是我先看的之一。
原因在于它的路线比较清楚:
- 它不是只想做最基础的向量相似度检索
- 它很认真地在做 hybrid search、sparse vector、多向量和 reranking 这类更贴近现代 RAG 的能力
- 同时它又没有把自己锁死在纯托管路线里
这意味着它适合一类很常见的现实需求:
- 一开始先自己搭
- 后面需要上生产
- 还想保留一定的部署自由度
如果你的 RAG 已经不再是“问一句答一句”的 demo,而是开始进入:
- 复杂 metadata filter
- keyword + semantic 的混合召回
- ColBERT 这类 late interaction rerank
- 多环境部署
那 Qdrant 的吸引力会明显提高。
4. Weaviate:适合想要更完整一体化体验的人
Weaviate 的风格和 Qdrant 有点像,但整体更偏“把很多东西直接给你准备好”。
它不是那种极瘦的底层引擎,而是更像一个完整的 AI database 方案。
如果你想要的是:
- 内建 hybrid search
- 和模型、向量化能力更自然地连起来
- self-hosted 和 managed 都能选
- 还希望多租户、压缩、过滤这些能力成体系
那它会很顺眼。
它比较适合有一定工程组织、希望少拼积木的团队。
代价也很直接:体系更完整,理解和接入它的整体模式也会更花时间。
5. Milvus / Zilliz Cloud:当你明确知道自己在走大规模路线
Milvus 我一般不会先推荐给刚开始写 RAG 的个人项目。
不是因为它不好,而是因为它更像在回答另一类问题:
- 数据规模很大怎么办
- 检索吞吐很高怎么办
- 分布式和云上生产怎么做
如果你已经进入更偏平台层的问题,Milvus 和它对应的托管方案 Zilliz Cloud 就会变得很有吸引力。
尤其是当你的需求开始接近:
- 向量量级很大
- 检索请求密度高
- 需要更强的分布式能力
- 不只是简单文本,还会用到 multi-vector 检索
这时候它就不是“大材小用”,而是在它擅长的地盘上。
6. Pinecone:用运维自由换工程省心
Pinecone 的优势一直都很清楚:少碰基础设施,尽快把应用做出来。
如果你团队现在最不想做的事情是:
- 管集群
- 调分片
- 折腾高可用
- 处理容量规划
那全托管路线会很舒服。
而且 Pinecone 现在的文档里把 dense、sparse、hybrid、metadata filtering、integrated embedding、serverless 成本模型这些都写得很明白,适合工程团队快速做出稳定路径。
但它的取舍也一样明显:
- 自由度没那么高
- 成本模型要认真看
- 供应商绑定感更强
- 某些底层行为你只能适应,不能完全掌控
所以它很适合“工程效率优先”的团队,不一定适合“基础设施控制权优先”的团队。
如果让我给一个很现实的选型建议
我大概会这样分:
你是个人开发者,或者两三个人的小团队
先看:
Chroma:如果你最在意的是本地开发体验和快速迭代Qdrant:如果你已经预感这个项目会继续长大
你已经确定要做生产 RAG
先看:
Qdrant:均衡、现代、部署选择多Weaviate:一体化强,少拼装Pinecone:如果你明确不想养基础设施
你在做平台型或大规模系统
先看:
Milvus / Zilliz Cloud- 再根据团队的云策略、运维能力和预算做细化
你还在做检索实验
先看:
FAISS
因为这时候你最该先回答的问题不是“我要上哪家数据库”,而是:
- 我的 embedding 模型靠谱吗?
- chunk 切法靠谱吗?
- top-k 合理吗?
- filter 和 rerank 会不会显著改善结果?
最后一句更重要
不要把数据库选型当成 RAG 成败的核心变量。
它当然重要,但真正决定效果上限的,往往还是这些:
- 你的语料是否干净
- chunk 和 metadata 是否设计合理
- 检索是否混合了关键词和语义
- 有没有做 rerank
- 注入给模型的上下文是不是克制而准确
换句话说,数据库决定你这套系统长得顺不顺,检索设计决定它答得准不准。
分块策略往往比数据库更直接影响效果
很多人做 RAG 的顺序是:
- 先选模型
- 先选数据库
- 最后才想怎么 chunk
但实际做下来,经常反过来更接近真相:你怎么分块,常常比你把块存进哪套数据库更影响召回质量。
因为检索系统真正比对的,不是原始整份文档,而是你切出来的那些块。
如果块切得很糟,后面无论是向量检索、关键词检索还是 hybrid,都会一起吃亏。
一个好的 chunk,通常要同时满足几件事:
- 足够小,能被精确召回
- 又不能太小,小到语义断裂
- 带着必要上下文,不至于只剩一句孤零零的话
- 最好保留结构信息,比如标题、章节、表格、代码块、版本号、时间

图 6:分块不是切得越整齐越好,而是切得越像完整证据越好。生产里很常见的路线,是结构感知分块,再配合父子分块把上下文带回来。
常见分块策略对比
| 策略 | 怎么做 | 优点 | 缺点 | 更适合什么 |
|---|---|---|---|---|
固定长度分块 | 按 token、字符或字数机械切开 | 最简单、最好实现、最适合先跑 baseline | 很容易把一句话、一个段落或一个代码块从中间切断 | 原型阶段、先做基线、数据结构很乱时 |
滑动窗口分块 | 固定长度 + overlap | 能缓解边界信息被切断的问题 | overlap 太大时会引入大量重复,召回和上下文都更噪 | 长文档、上下文跨段频繁的资料 |
按句子 / 段落语义分块 | 尽量沿自然语义边界切 | 语义更完整,块更像“可被引用的证据” | 需要更干净的预处理;块长度可能不均匀 | 说明文档、知识库、报告、笔记 |
结构感知分块 | 按标题、章节、表格、列表、代码函数、API 段落切 | 最接近文档原意,最适合保留上下文结构 | 实现比固定切块复杂,对解析质量有要求 | 技术文档、政策文档、代码文档、手册 |
父子分块 / Small-to-Big | 检索时用小块,返回时带回父段或父文档窗口 | 兼顾精确召回和足够上下文,是生产里很常见的折中 | 索引和返回逻辑更复杂,需要维护 parent-child 关系 | 企业 RAG、长文档 QA、需要引用上下文的系统 |
我会怎么选分块起点
如果你现在还没有明确答案,我会给一个很务实的起步顺序:
1. 纯文本知识库
优先尝试:
结构感知分块- 如果结构很差,再退回到
段落分块 + 轻度 overlap
这类文档里,标题、列表、章节边界通常非常值钱。
如果你直接机械切,很容易把“定义”和“限定条件”拆开。
2. API 文档、技术手册、代码说明
优先尝试:
- 按
函数 / 类 / 接口 / 标题段切 - 不要把代码块和解释段强行拆开
这类语料经常同时依赖:
- 标识符
- 代码片段
- 参数表
- 邻近解释
如果只按长度切,效果往往会很漂。
3. 法务、制度、合同、合规材料
优先尝试:
- 按
条款 / 章节 / 条目切 - 强化 metadata,比如版本、生效日期、地区、主体
因为这类资料最怕的不是“没召回到”,而是“召回了一段长得很像、但版本不对的内容”。
分块上最常见的几个坑
1. overlap 开太大
很多人以为 overlap 越大越安全,结果是:
- 索引里重复块暴涨
- top-k 结果互相长得太像
- 送给模型的上下文越来越冗余
overlap 不是越大越好,它只是边界修补工具,不该变成“靠重复补效果”。
2. 只切正文,不保留标题和结构
很多关键语义其实不在正文句子里,而在:
- 章节标题
- 表头
- 小节名
- 列表项层级
这些东西一丢,块表面上还在,意义却已经变浅了。
3. 为了统一长度,把所有东西都切成一样大
这通常只对机器处理友好,不一定对检索友好。
真实世界的资料天然就不整齐,检索系统也没必要假装它们整齐。
召回策略别只理解成“向量检索”
很多新手一说召回策略,脑子里只有一件事:embedding + vector search。
但在现代 RAG 里,召回至少可以分成两层来看:
- 第一层:先把候选找出来
- 第二层:再把这些候选重新排序
第一层决定 recall,第二层决定 precision。
很多系统答不好,并不是第一层完全没找到,而是第二层没把真正该看的块排到前面。

图 7:把召回拆成两层会更容易想清楚问题在哪。第一层先扩大候选池,第二层再做重排,这比把 top-k 直接塞给模型稳得多。
第一层召回:几种常见方式对比
| 方式 | 强项 | 弱点 | 适合什么问题 |
|---|---|---|---|
关键词 / BM25 | 对精确术语、错误码、函数名、型号、专有名词很强 | 对同义表达、改写、自然语言概括不够强 | 代码检索、日志检索、产品型号、法规条目 |
Dense 向量检索 | 对语义相近、改写表达、自然语言问题很强 | 对短标识符、稀有术语、精确字符串可能不稳 | FAQ、知识库问答、解释型问题 |
Sparse 检索 | 保留词项层面的可解释性,又比纯 BM25 更灵活 | 仍然偏词项空间,不是对所有语义改写都足够强 | 需要兼顾稀有词和一定语义泛化的语料 |
Hybrid 检索 | 同时吃到关键词和语义召回的好处,最像生产默认值 | 系统更复杂,需要调融合方式和权重 | 大多数企业文本型 RAG |
Metadata 过滤 + 检索 | 先把范围缩小,能显著减少错召回 | metadata 设计差时,容易过筛,把有用结果先滤掉 | 多版本、多地区、多部门、多租户语料 |
Multi-query / Query Rewrite | 能把用户一句模糊问题拆成多个更容易召回的查询 | 会增加成本和链路复杂度;重写差时会带偏方向 | 长问题、模糊问题、专业术语不稳定的问题 |
第二层排序:为什么 rerank 几乎成了现代 RAG 的标配
如果第一层召回拿回来的只是“差不多相关”的 20 条候选,那么第二层 rerank 的作用,就是把真正最该进上下文的那几条推到前面。
这一步常见价值非常大,尤其是在:
- hybrid 已经把候选池放宽了
- 数据里存在很多“看起来都像相关”的段落
- 问题问得很细,但文档很长
你可以把它理解成:
- 第一层负责“别漏掉”
- 第二层负责“别把错的放前面”
对很多生产系统来说,没有 rerank 的 top-k,往往只能算“半成品召回”。
我会怎么理解这几种召回路线
1. 纯关键词路线
不是过时,而是在很多精确匹配场景里依然非常能打。
例如:
- 报错码
- 函数名
- 配置项
- 产品型号
- 合同条款编号
这些东西有时 dense vector 反而没那么稳。
2. 纯向量路线
适合回答“意思相近但表述不一样”的问题。
如果你的用户很少按文档原话提问,而更像自然语言聊天,向量检索的价值就会更大。
但它的短板也很明显:它不天然擅长精确字符串世界。
3. Hybrid 路线
如果你现在问我“默认先试哪条路”,我还是会说:先试 hybrid。
原因很简单,现实语料往往两种需求都存在:
- 有些问题靠精确词
- 有些问题靠语义相似
把这两类都交给单一路线,通常都不够稳。
4. Query Rewrite / Multi-query
它更像召回层的“放大器”。
当用户问题非常口语化、过于短、或者本身不够像索引里的表达时,这一步会很有帮助。
但它不是第一优先级。通常更稳的顺序是:
- 先把 chunk 和 hybrid 做好
- 再上 rerank
- 还不够,再考虑 rewrite / multi-query
如果硬要说“行业最优解”,我更愿意给一个默认答案
先把话说在前面:RAG 没有一个对所有行业、所有语料、所有预算都成立的单一最优解。
但如果你的问题是:
“那截至现在,行业里更稳、更常见、成功率更高的默认路线是什么?”
那我会给出一个相对明确的回答:
对大多数文本型企业 RAG,当前更像“行业默认强解”的组合是
结构感知分块为主父子分块 / small-to-big保留上下文metadata filter先收窄范围- 第一层用
hybrid retrieval - 第二层加
rerank - 返回给模型时做
parent expansion + 去重 + 来源标注 - 整个系统用一套小型评估集持续回归
如果只把它压成一句话,大概就是:
结构感知分块 + metadata + hybrid + rerank + parent context expansion + evaluation loop。
这不是唯一答案,但它确实越来越像很多成熟 RAG 系统的共同收敛方向。

图 8:如果只给团队一个默认起手式,我会更愿意给这样一段台阶式流程。它不一定最省,但通常是最不容易从一开始就做歪的路线。
为什么这套组合更像当前主流最优解
1. 它不赌单一能力
它不假设:
- 只靠向量就够
- 只靠关键词就够
- 只靠大 chunk 就够
- 只靠 top-k 就够
而是把每一层都做成互补关系。
2. 它对真实企业语料更友好
真实企业语料通常有这些特征:
- 文档很长
- 版本很多
- 术语很多
- 结构并不总是干净
- 用户提问方式也不统一
这种情况下,单一路线往往很容易偏科。
3. 它更容易做错误定位
如果你的链路是:
- 分块
- metadata
- hybrid
- rerank
- context assembly
那你出问题时可以更清楚判断:
- 是 chunk 有问题
- 是 filter 过严
- 是 first-pass recall 不够
- 还是 rerank 没把对的块顶上来
相比之下,单层黑盒路线很难排查。
但“行业最优解”也会按语料类型变形

图 9:同样是 RAG,语料类型不同,默认策略也会变形。知识库更重结构,代码支持更重精确词,法务合规则更重版本和过滤。
文档 / 知识库型 RAG
默认优先:
- 结构感知分块
- hybrid
- rerank
- parent expansion
代码 / 技术支持型 RAG
默认优先:
- 按函数、类、接口、错误码附近切块
- 更重视关键词 / BM25 能力
- hybrid 几乎总比纯 dense 更稳
合规 / 法务 / 政策型 RAG
默认优先:
- 按条款或章节切
- 极强的 metadata filter
- 版本、生效时间、地区过滤必须前置
因为这类系统最大的风险通常不是“答慢了”,而是“引用错版本了”。
如果你只能给团队一个默认起手式
我会给这个:
- 先做
结构感知分块 - 每个 chunk 带完整 metadata
- 第一层直接上
hybrid - top-k 候选后面接
rerank - 最后返回父段落或父文档窗口,而不是只丢碎片句子
- 用 30 到 100 个真实问题做评估集
这套东西不一定一步到位最省钱,但它很像目前“最不容易把系统做歪”的起点。
真正实用的落地顺序,通常是这四步
很多团队一上来就想做全能 Agent,我反而建议先收着点。

图 10:这更像一段该按顺序爬的楼梯。先把检索和上下文打稳,再慢慢加工具、自动化和多 Agent,通常比一开始全开更可靠。
第一步:先把检索做好
先解决最基本的问题:
- 文档从哪里来
- 如何切分
- 用什么检索
- 召回质量怎么评估
如果连“找对材料”都还没稳定,后面再叠 Agent,只会把错误放大。
第二步:把检索结果变成干净的上下文
不要把十几篇文档整段扔给模型。
应该做的是:
- 去重
- 截断
- 标注来源
- 保留必要元数据
- 控制每轮真正进入上下文的证据量
这一步看起来不花哨,但对效果影响非常大。
第三步:只给 Agent 最小可用工具集
如果任务需要行动,再慢慢加工具。
一开始最好只开放少量、高价值、低风险的能力,比如:
- 搜索
- 读文件
- 查数据库
- 发消息
- 创建任务
工具不是越多越好,越多越容易让模型在错误路径上乱跑。
第四步:最后再上自动化和多 Agent
等单 Agent 稳了,再考虑:
- 定时执行
- webhook 触发
- 子 Agent 委派
- 并行工作流
因为这些能力一旦接进生产,问题就不再只是“答错了”,而是“做错了”。
我现在最在意的几个误区

图 11:很多 RAG 系统不是败在一个大错上,而是败在一串小误区叠起来。把这些坑先避开,常常比继续换模型更有效。
1. 用 Agent 解决本来只需要搜索的问题
这会让简单问题变慢、变贵,还更不稳定。
2. 只做向量检索,不做关键词和过滤
很多业务问题其实同时依赖精确词匹配和语义相似,混合检索往往更稳。
3. 没有 rerank,就直接把 top-k 塞给模型
首轮召回常常只是“差不多有关”,不代表真的最相关。
4. 把长期记忆当成事实真相
记忆适合帮助模型“更懂你”,但不应该替代权威资料。
5. 没有评估集,只凭感觉调 RAG
RAG 的问题很多时候不是生成问题,而是召回问题。没有具体样本集,基本无从判断到底是哪一层出了错。
一个够用的总体理解
如果非要把它们压缩成一句话,我会这样说:
RAG 负责把信息找回来,Agent 负责把事情做下去。
前者解决“模型现在缺什么上下文”,后者解决“模型接下来该采取什么动作”。
真正好用的系统,往往不是把两者混成一团,而是让它们各自做自己最擅长的部分,再通过干净的上下文边界接起来。
对很多个人项目和团队系统来说,最稳的路线其实也不复杂:
- 先做可评估的检索
- 再做干净的上下文注入
- 再加有限工具
- 最后才谈自动化、调度和多代理协作
这样长出来的系统,通常会比“一步到位的全能 Agent”更便宜,也更可靠。

图 12:如果把整篇压成一张图,大概就是这张总览板。先判断问题,再分清边界,再把检索链路搭稳,最后才去谈工具、自动化和多 Agent。
如果后面我继续整理这批资料,我还想再单独写两篇:一篇聊 RAG 里的 chunk、metadata、rerank 到底怎么取舍,另一篇聊 Agent 里的工具边界、记忆设计和自动化触发器怎么搭。那会更偏实现层,也更接近真正上线时会踩的坑。
附:龙珠风补充图集
这组补充图集把文章里的几个核心判断,压缩成了更偏“热血分镜”的速读版:先区分 RAG 和 Agent 的分工,再看检索到行动的交接,再把历史、记忆、RAG 证据拆开,最后回到真正实用的落地顺序。

补充图 1:先看总览。RAG 负责把当前任务缺的上下文找回来,Agent 负责接着把任务推进下去。
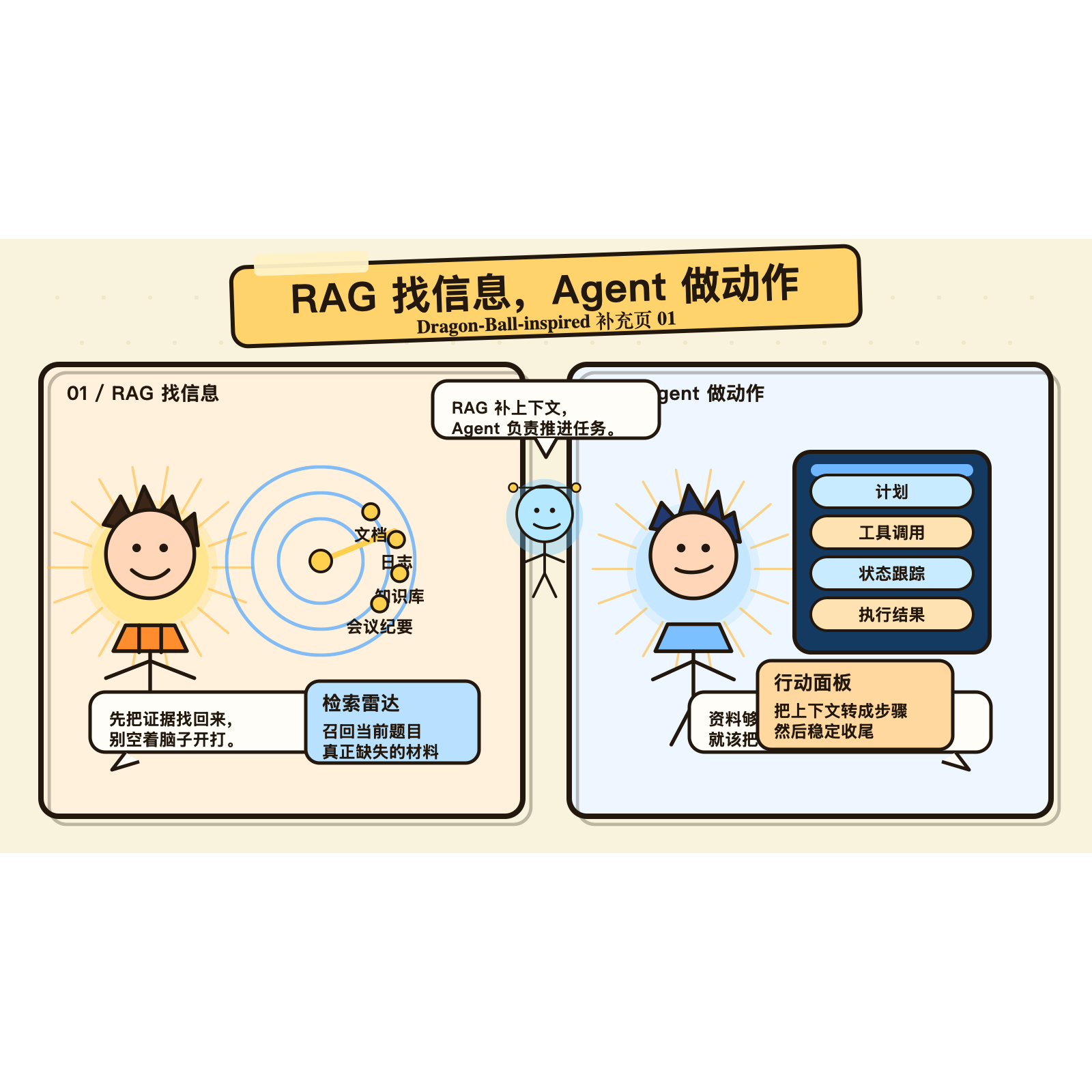
补充图 2:把分工说得再直白一点。RAG 更像证据雷达,Agent 更像执行面板。
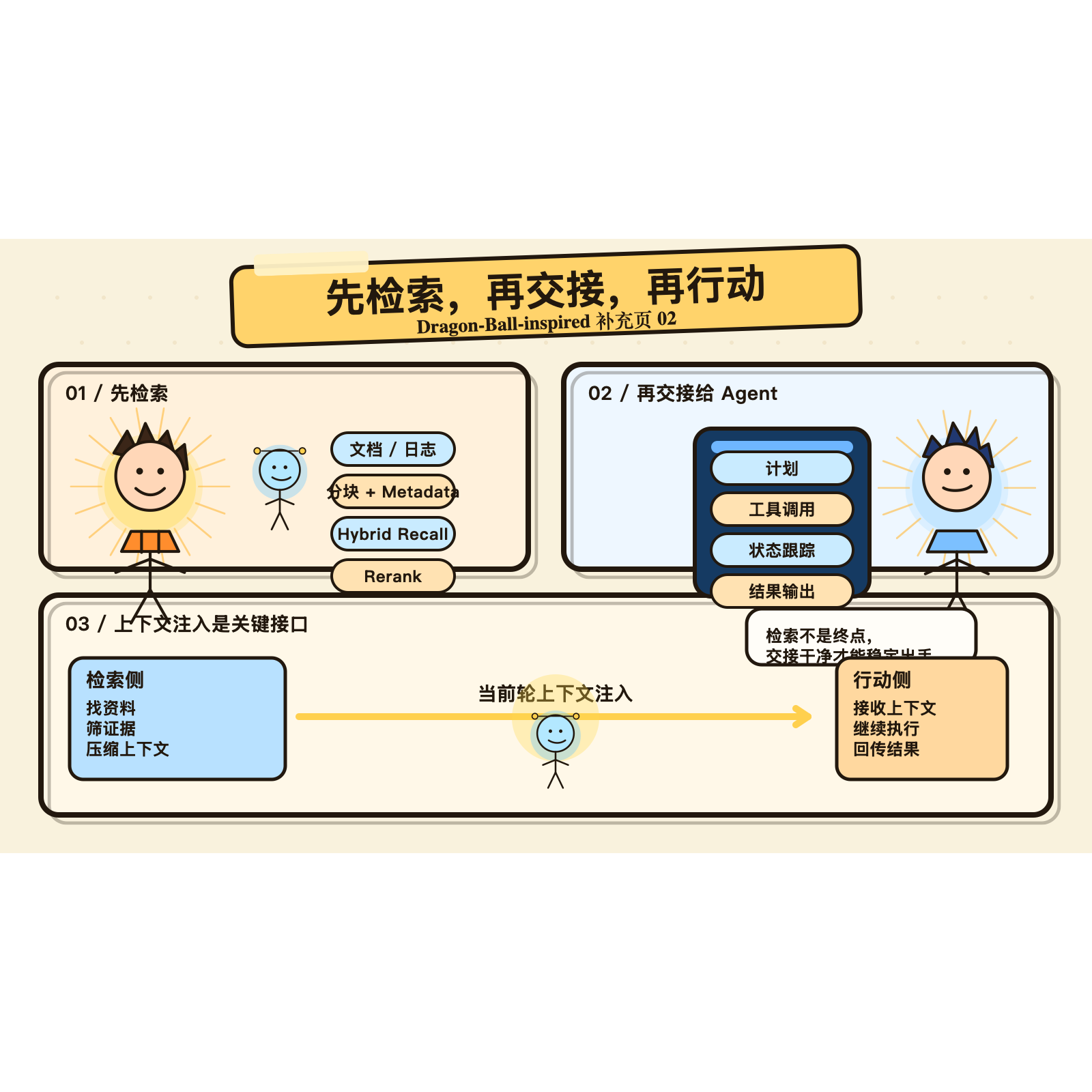
补充图 3:检索和行动之间,真正重要的是交接接口。检索不是终点,干净的上下文注入才是关键。
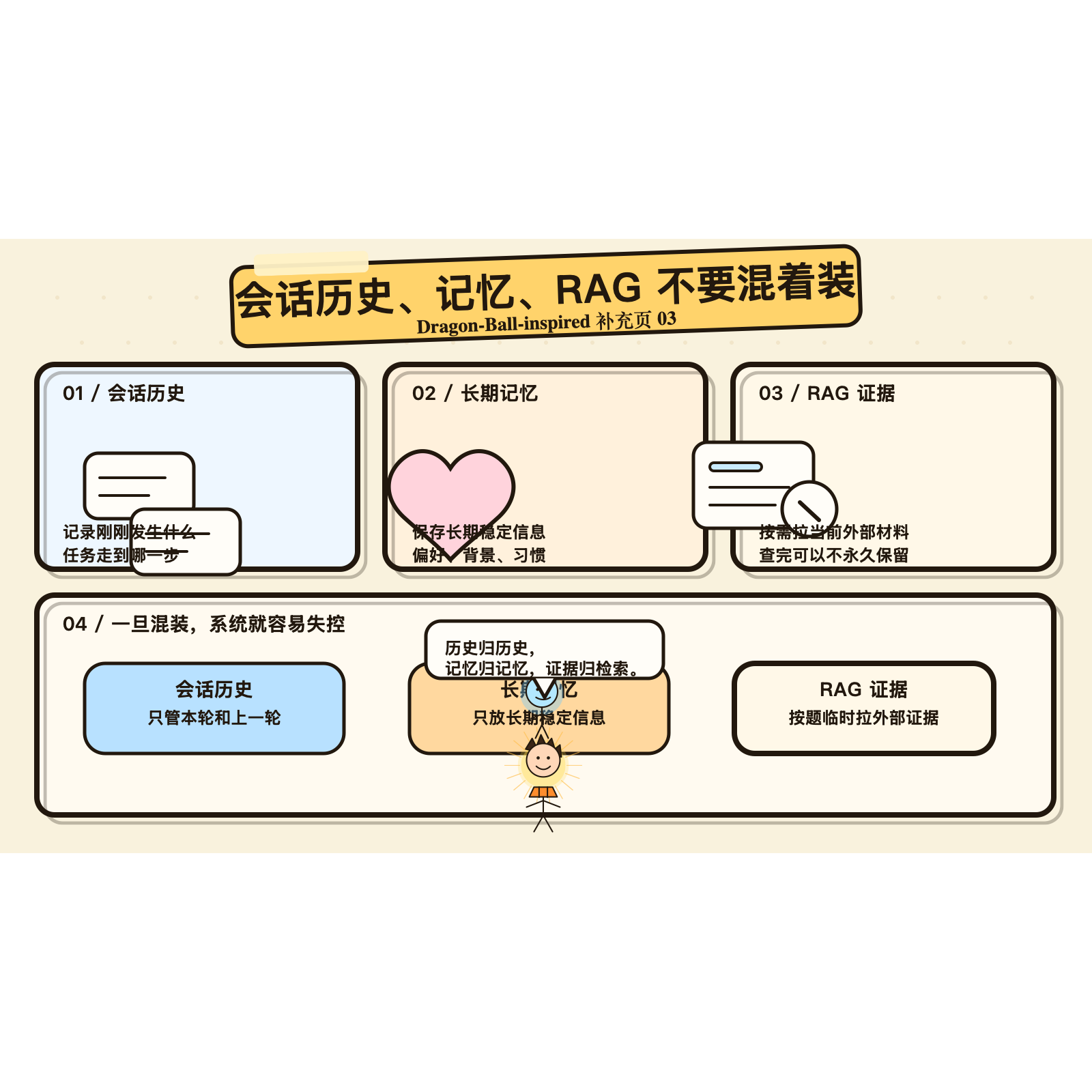
补充图 4:会话历史、长期记忆、RAG 证据最好各归各位。边界一乱,系统就很容易一起乱。
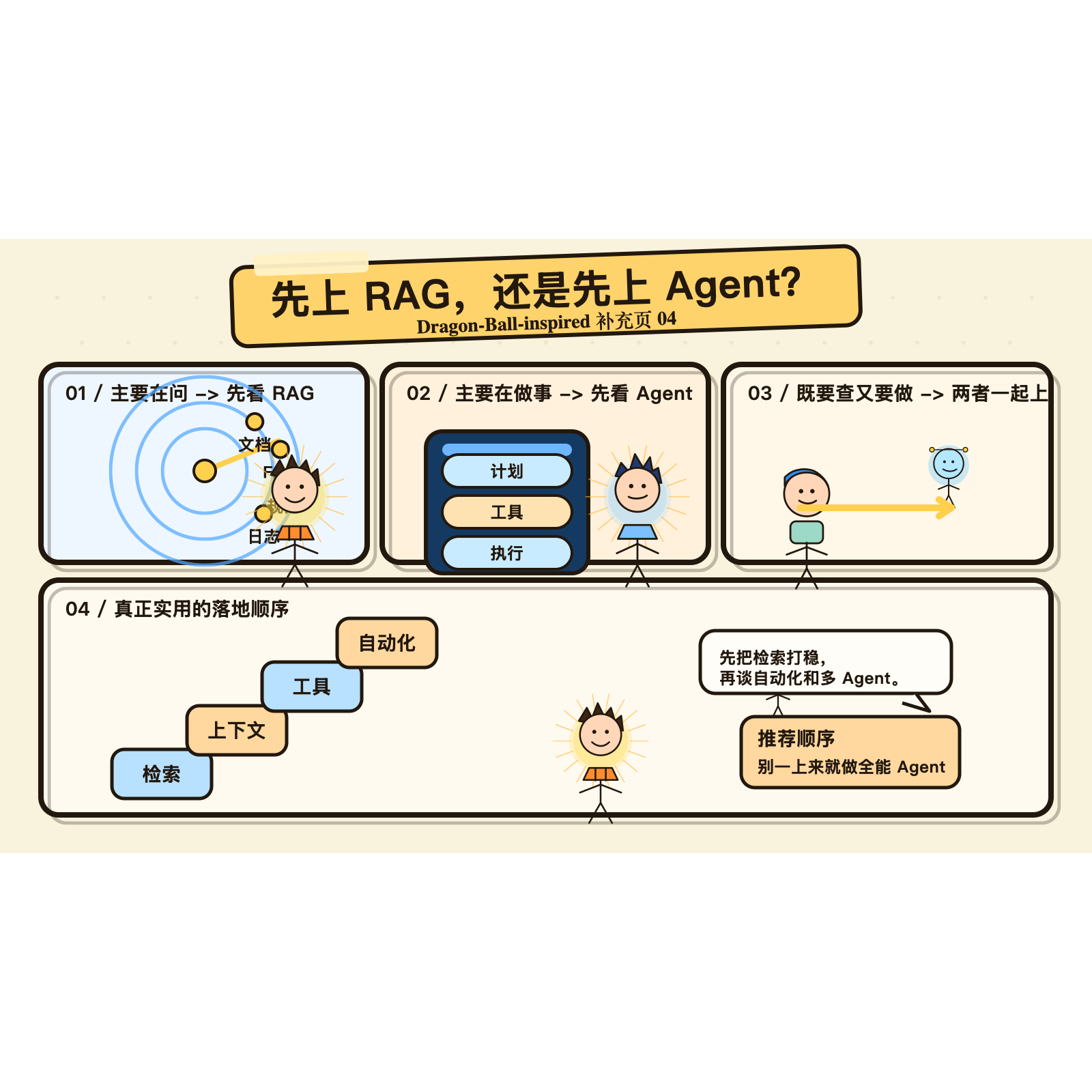
补充图 5:真正实用的起手顺序,通常还是先把检索和上下文打稳,再慢慢加工具、自动化和多 Agent。