RAG 和 Agent 别再混着用了:一篇讲清分工、组合与落地顺序
2025年6月12日 · 1069 字 · 6 分钟 · RAG Agent AI LLM 架构
封面图:如果把这篇先压成一眼能懂的画面,大概就是这样。左边负责把资料和证据找回来,右边负责拿着上下文把事做下去,中间最关键的是交接。
这两年很多 AI 产品介绍里,RAG 和 Agent 经常被放在一起讲,听久了很容易产生一种错觉:只要模型会检索、会调用工具、会多轮推理,这些东西差不多就是一回事。
但真到了落地阶段,这种混用会很快带来问题。有人把本来适合做检索问答的系统做成了复杂 Agent,结果成本高、延迟大、稳定性差;也有人把本来需要行动能力的任务硬塞进 RAG,最后模型只能“知道”,却做不了事。
最近整理了一批本地资料,里面既有检索、向量库、混合搜索,也有工具调用、上下文注入、自动化和多代理协作。抽出来以后,我越来越觉得:RAG 和 Agent 最重要的不是谁更高级,而是它们解决的问题完全不同。
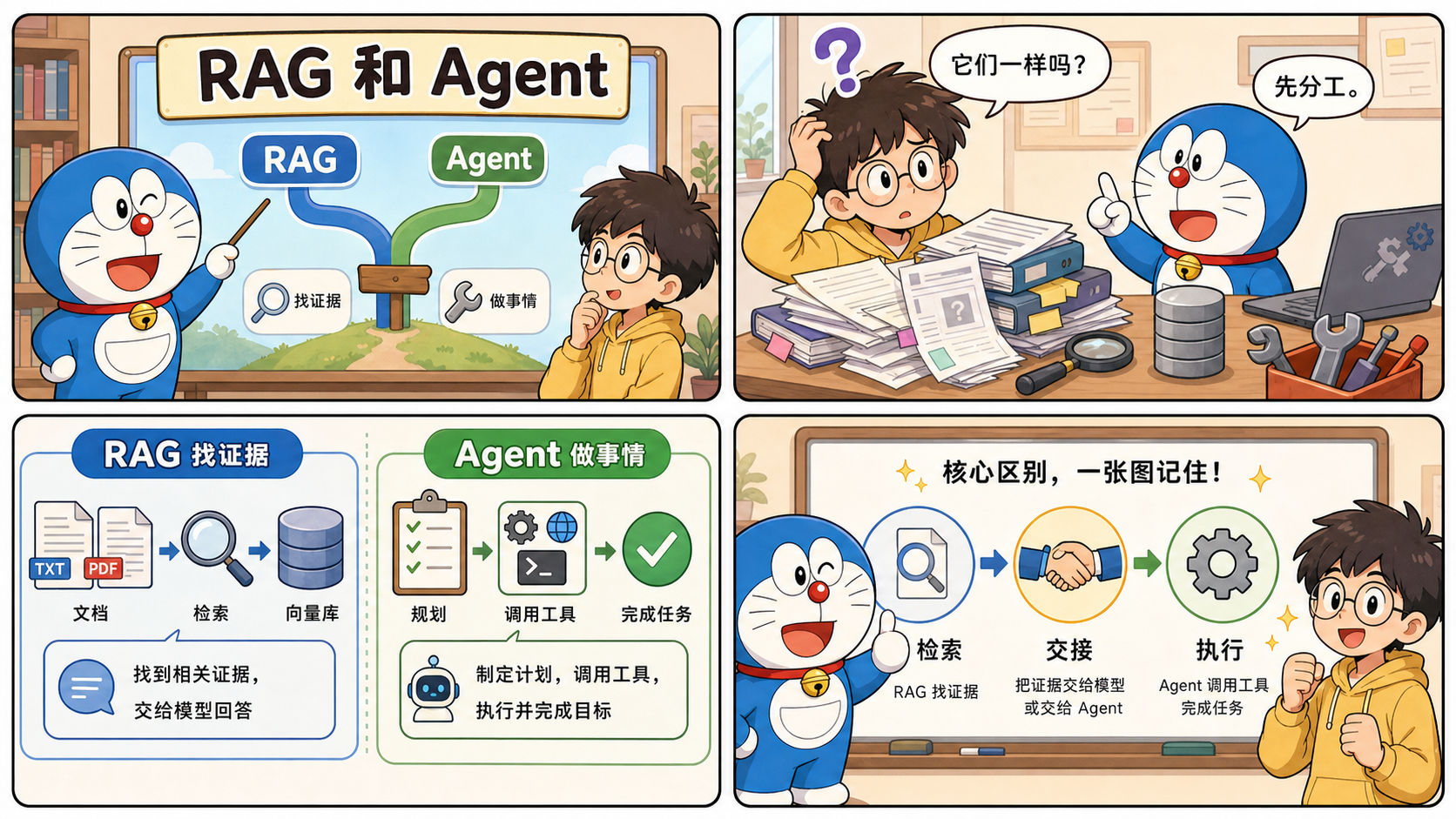
图 1:把它们想成两种不同角色会更好理解。RAG 更像先把资料和证据找对的人,Agent 更像拿着上下文和工具把事情做下去的人。
RAG 解决的是“模型不知道”的问题
RAG,检索增强生成,本质上是在回答前先补证据。
它最适合的场景通常有几个共同点:
- 问题依赖外部知识,而这些知识不稳定、更新快,或者根本不在模型参数里
- 你希望回答尽量基于真实文档,而不是模型自由发挥
- 你更关心“答得准不准”,而不是“会不会自己行动”
比如:
- 企业内部知识库问答
- 产品文档搜索
- 法务、金融、医疗类的资料辅助查询
- 会议纪要、笔记、日报的语义搜索
这类问题的核心不是“推理链多长”,而是能不能先把对的材料找回来。
所以一个像样的 RAG 系统,重点通常都落在这些地方:
- 文档怎么切分,既不丢语义,又不让块太大
- 元数据怎么设计,能不能按时间、部门、来源做过滤
- 检索是不是只靠向量,还是需要关键词 + 向量的混合检索
- 首轮召回之后,要不要再做 rerank
- 最后拼进上下文的内容是不是有重复、冲突或者噪音
说白了,RAG 的第一目标不是“聪明”,而是把上下文准备对。
Agent 解决的是“模型知道了以后要怎么做”的问题
Agent 则完全是另一类能力。
它关心的不是有没有资料,而是模型能不能围绕一个目标,调用工具、拆分步骤、处理中间状态,并最终把事情做完。
典型任务包括:
- 读一个 GitHub issue,然后修改代码、跑测试、提交结果
- 收到告警后先查日志、再定位服务、最后生成排障摘要
- 定时执行例行任务,比如日报、巡检、内容聚合、监控
- 在多平台之间转发、整理、归档信息
这类任务即使完全不需要 RAG,依然需要 Agent,因为难点不在知识召回,而在:
- 如何规划下一步动作
- 什么时候该调用哪个工具
- 工具失败后怎么重试或降级
- 中间产物是否需要保存
- 任务什么时候可以安全结束
如果说 RAG 像“先去图书馆找参考资料”,那 Agent 更像“拿着目标开始干活的人”。